


Target Appearance
Our DyNCA model learns a desired texture pattern from a given target
appearance image.











Current Dynamic Texture Synthesis (DyTS) models can synthesize realistic videos. However, they require a slow iterative optimization process to synthesize a single fixed-size short video, and they do not offer any post-training control over the synthesis process. We propose Dynamic Neural Cellular Automata (DyNCA), a framework for real-time and controllable dynamic texture synthesis. Our method is built upon the recently introduced NCA models and can synthesize infinitely long and arbitrary-sized realistic video textures in real time. We quantitatively and qualitatively evaluate our model and show that our synthesized videos appear more realistic than the existing results. We improve the SOTA DyTS performance by 2∼4 orders of magnitude. Moreover, our model offers several real-time video controls including motion speed, motion direction, and an editing brush tool. We exhibit our trained models in an online interactive demo that runs on local hardware and is accessible on personal computers and smartphones.
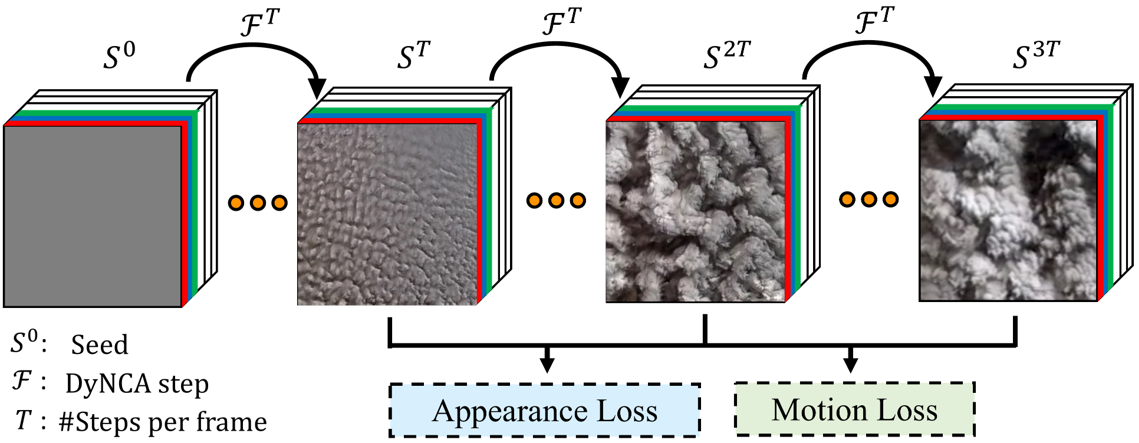
Starting from a seed state, DyNCA iteratively updates it, generating an image sequence. We extract images from this sequence and compare them with an appearance target as well as a motion target to obtain the DyNCA training objectives. After training, DyNCA can adapt to seeds of different height and width, and synthesize videos with arbitrary length. Sequentially applying DyNCA updates on the seed synthesizes dynamic texture videos in real-time.
The figure below illustrates a single DyNCA step.
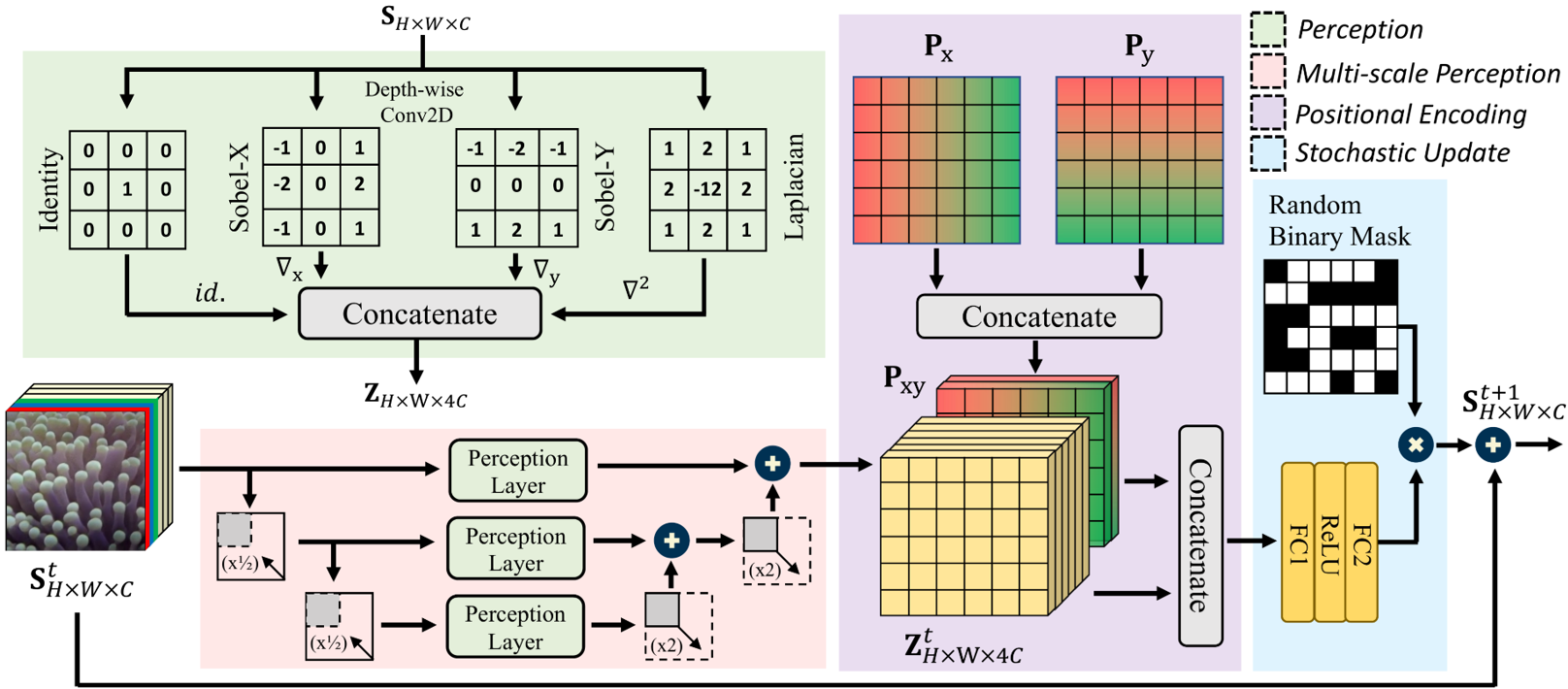
Given an input state $\mathbf{S}^t \in R^{H \times W \times C}$ at time step $t$, each cell perceives its neighbors on various scales with the same perception layer. The perception tensor of each scale is then upsampled and summed up, and is concatenated with the positional encoding tensor $\mathbf{P}_{xy}$. Each cell $s^t_{ij}$ then applies the same update rule, parametrized by a small neural network. Finally, all cells perform stochastic residual update to determine the state of the cells in time $t + \Delta t$.
Our DyNCA model learns a desired texture pattern from a given target
appearance image.
Our model can learn motion from a target video and transfer this motion to the target
appearance image.
Our model synthesizes realistic dynamic texture videos. Each synthesized video frame resembles the target appearance, while the the concatenation of frames induces the motion of the target dynamics.
@InProceedings{pajouheshgar2022dynca,
title = {DyNCA: Real-Time Dynamic Texture Synthesis Using Neural Cellular Automata},
author = {Pajouheshgar, Ehsan and Xu, Yitao and Zhang, Tong and S{\"u}sstrunk, Sabine},
booktitle = {Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2023},
}